Knax Shop Website Localization
May 14, 2015 admin 0 Comments
The first project I worked on was the KNAX Shop Website Localization. KNAX Shop is an online business held by a Dane Jacob Nielsen who sells innovative Danish-designed wall hooks:

The Team:

Jacob lives in France, and he had his website in 3 languages: Danish (the source language), English and French. The CMS he uses is called PrestaShop – this is a free eCommerce solution that now has 230,000 users.
I worked with John Di Rico, Josh Potter and Duncan Young.
In order to manage the project, we used a free cloud-based Project Management tool called Zoho Project.
My part included leveraging the old version of the website in order to create a base Translation Memory and glossaries.
Josh did the most challenging part of the project – he extracted the strings from the website in three languages: Danish, English and French.
Then we aligned the file pairs using the Wordfast Anywhere alignment tool and built an EN-DA TM as well as an EN-FR TM.
I was in charge of creating glossaries, and I did some research to find out what the best way is to extract terms from files automatically.
I first used Tilde.com, which is a free cloud-based solution powered by TAAS. But I was not happy with the results as it extracted very few bilingual terms. It is good in extracting monolingual terms, though.
I also tried SDL Multiterm Extract for the automatic term extraction from bilingual files. For the En-Fr pair, it only extracted 20 terms, which is too few, so I would not advise buying it.

Finally, AntConc is really good for monolingual term base extraction as it is a free solution that extracts a lot of terms (230 per 1000 words) and indicated frequency.
But I am a memoQ user, and I ended up using memoQ for leveraging monolingual files and matching the results.

Here is how the process looks:
1. Add a Stop Word List

MemoQ has a very limited number of Stopword lists – besides, these lists are too short. SDL Trados Studio provides long and very good SWL for a lot of languages.
However, adding them to memoQ can be a challenge as SWL in memoQ have their own syntax and extension (.mqres). Here is how you can do it:
– go to Resource Console – Stopword Lists
– export a SWL from memoQ (.mqres) to get mqres syntax (open in in Notepad++ or TextWrangler)
– add it to a Word document
– add an SDL SWL to the above Word file
– format it using wildcards to observe the .mqres syntax
– import it back to memoQ: give it a name, specify the language
- Extract two monolingual glossaries:
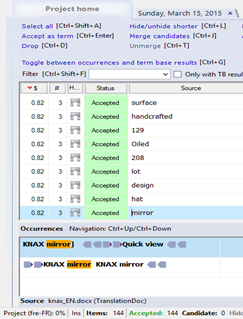
– go to Options – Extract Terms
– indicate the frequency and add a Stopword list
– generate candidates, accept them and export them to a memoQ termbase
– export the termbase as a csv file
3. Now that you have two columns (En-Fr, for example), you can compare and match them. First, convert the csv to Excel, then sort the left column alphabetically and start comparing and populating the right column.
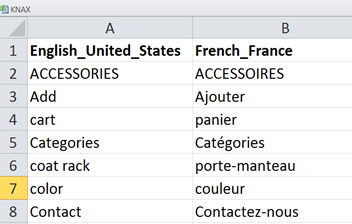
4. Bonus
I also had to generate an En-Da glossary, but I do not speak Danish. So, I used Google Translate to do back translation.
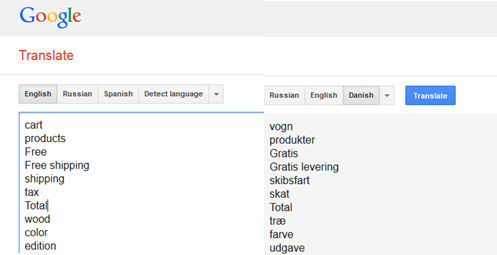
Then I pasted the Danish translation done by Google Translate back to the Excel file as the third column and then started comparing – I now had a column in English and two columns in Danish (one was human-translated (leveraged from the website), the other was machine-translated, but 80% of Danish terms in those two columns were the same).
As a result, I generated 70 terms for En-Fr and En-Da language pairs, without speaking Danish!
When I attended the Google Translate workshop in Google, the GT speakers asked the audience: “What are the unusual ways you use Google Translate?” I shared this example, and the Google Translate speakers were apparently glad to hear it as they have never thought that GT could be used in this way.